
Chào các bạn đang theo dõi khóa học lập trình trực tuyến ngôn ngữ C++.
Sau khi tìm hiểu một số khái niệm cơ bản về con trỏ, cấp phát động, … chúng ta đã thấy được dãy địa chỉ bộ nhớ ảo được chia thành nhiều phân vùng khác nhau và được sử dụng cho những mục đích khác nhau. Trong bài học này, mình sẽ cùng các bạn tổng hợp lại chức năng của một số phân vùng trên bộ nhớ ảo.
Dưới đây là hình ảnh minh họa cho thứ tự các phân vùng trên bộ nhớ ảo:

Code segment
Code segment (text segment) là nơi mà lưu trữ các mã lệnh đã được biên dịch của các chương trình máy tính. Những mã lệnh trong phân vùng này sẽ được chuyển đến CPU xử lý khi cần thiết. Code segment chỉ chịu sự chi phối của hệ điều hành, các tác nhân khác không thể can thiệp trực tiếp đến phân vùng này. Việc đưa các mã lệnh đã được biên dịch của chương trình lên phân vùng code segment là công việc đầu tiên mà hệ điều hành cần làm khi chúng ta chạy chương trình.
Data segment
Data segment (initialized data segment) là phân vùng mà hệ điều hành sử dụng để khởi tạo giá trị cho các biến kiểu static, biến toàn cục (global variable) của các chương trình.
BSS segment
BSS segment (uninitialized data segment) cũng được dùng để lưu trữ các biến kiểu static, biến toàn cục (global variable) nhưng chưa được khởi tạo giá trị cụ thể.
Heap segment
Heap segment (free srote segment) được sử dụng để cấp phát bộ nhớ thông qua kỹ thuật Dynamic memory allocation.
Để sử dụng kỹ thuật cấp phát bộ nhớ động, ngôn ngữ C++ đã hổ trợ sẵn cho chúng ta toán tử new. Ví dụ:
new int; //allocate 4 bytes on Heap segment
new int[10]; //allocate (4 * 10) bytes on Heap segment
Toán tử new sau khi thực thi thành công sẽ trả về địa chỉ của vùng nhớ được cấp phát trên heap, chúng ta có thể sử dụng con trỏ có kiểu dữ liệu phù hợp để lưu trữ địa chỉ trả về này, và con trỏ cũng là công cụ duy nhất giúp chúng ta có thể xác định được vị trí vùng nhớ được cấp phát là ở đâu, và cũng thông qua con trỏ để chúng ta có thể giải phóng vùng nhớ đã được cấp phát.
int *pInt = new int;
int *pArr = new int[10];
Chúng ta không cần biết rõ cơ chế quản lý bộ nhớ Heap như thế nào, mà chỉ cần biết rằng bộ nhớ được cấp phát trên Heap sẽ không tự giải phóng cho đến khi nào toàn bộ chương trình đang chạy kết thúc. Do đó, nếu chương trình có thời gian chạy quá lâu mà không được giải phóng các vùng nhớ một cách hợp lý, điều này sẽ làm ảnh hưởng đến việc cấp phát bộ nhớ động cho các chương trình khác.
Mình có thể kể ra một số ưu điểm và nhược điểm đáng chú ý khi sử dụng phân vùng Heap như sau:
- Việc cấp phát bộ nhớ trên Heap chậm hơn các phân vùng khác.
- Vùng nhớ đã được cấp phát sẽ vẫn thuộc quyền kiểm soát của chương trình đang chạy cho đến khi chúng được giải phóng, hoặc nhận được tín hiệu kết thúc chương trình.
- Vùng nhớ được cấp phát phải được quản lý bởi ít nhất 1 con trỏ.
- Toán tử dereference truy xuất đến vùng nhớ chậm hơn các biến thông thường.
- Phân vùng Heap có dung lượng lớn nhất, nên chúng ta có thể sử dụng một cách thoải mái hơn các phân vùng khác.
Stack segment
Call Stack (thường được gọi là Stack) được dùng để cấp phát bộ nhớ cho tham số của các hàm (function parameters) và biến cục bộ (local variables). Call Stack được thực hiện theo cấu trúc dữ liệu stack, do đó, trước khi nói về phân vùng Stack trên bộ nhớ ảo mình sẽ trình bày cho các bạn về cấu trúc dữ liệu stack trước.
Stack data structure
Stack là một cơ chế tổ chức dữ liệu. Các bạn cũng từng làm việc với một kiểu tổ chức dữ liệu khá phổ biến là mảng một chiều. Mỗi cấu trúc dữ liệu sẽ tổ chức dữ liệu dưới một cơ chế khác nhau để sử dụng hiệu quả trong từng công việc cụ thể. Bây giờ chúng ta xem xét cấu trúc dữ liệu stack.
Dưới đây là một hình ảnh minh họa cho một stack trong đời sống hằng ngày:

Những đĩa CD này được đặt chồng lên nhau. Khi nhìn vào chồng đĩa CD này, chúng ta chỉ có thể thực hiện 3 công việc:
(1) Nhìn vào đĩa CD trên cùng của chồng đĩa.
(2) Lấy ra một đĩa CD nằm trên cùng.
(3) Đặt thêm một đĩa CD lên trên cùng của chồng đĩa.
Do đó, chúng ta có thể nhận thấy ngay việc tổ chức dữ liệu theo cơ chế stack gặp nhiều hạn chế hơn so với tổ chức dữ liệu theo mảng một chiều.
Khi sử dụng mảng một chiều, chúng ta có thể truy cập vào bất kì phần tử nào bên trong mảng bằng cách đưa ra chỉ số của phần tử. Nhưng đối với stack thì không được. Chúng ta chỉ có thể thao tác với phần tử nằm trên cùng (ngoài cùng). Chúng ta thường nói stack hoạt động theo cơ chế “Last-in, first-out”. Có nghĩa là phần tử nào được thêm vào mảng sau cùng thì sẽ được lấy ra đầu tiên.

Ví dụ:
Stack ban đầu của chúng ta là
--------------------------------
| 4 7 2 5
--------------------------------
Thêm vào phần tử có giá trị là 3
--------------------------------
| 4 7 2 5 3
--------------------------------
Thêm vào phần tử có giá trị 9
--------------------------------
| 4 7 2 5 3 9
--------------------------------
Lấy một phần tử ra khỏi stack
--------------------------------
| 4 7 2 5 3
--------------------------------
Call Stack segment
Call stack segment cũng hoạt động dựa trên cơ chế tổ chức dữ liệu như stack. Khi bắt gặp một dòng lệnh khai báo biến, nếu biến đó là biến cục bộ hoặc tham số hàm, nó sẽ được cấp phát tại địa chỉ lớn nhất hiện tại trên Stack. Khi một biến cục bộ hoặc tham số của hàm ra khỏi phạm vi khối lệnh, nó sẽ được đưa ra khỏi Stack.
Để kiểm chứng điều này, các bạn có thể chạy thử đoạn chương trình sau:
int main()
{
int n1, n2, n3, n4, n5;
cout << "Address of " << &n1 << endl;
cout << "Address of " << &n2 << endl;
cout << "Address of " << &n3 << endl;
cout << "Address of " << &n4 << endl;
cout << "Address of " << &n5 << endl;
return 0;
}
Đoạn chương trình này khai báo lần lượt 5 biến cục bộ liên tiếp nhau. Nếu trong trường hợp tại thời điểm khai báo, chỉ có chương trình này được CPU xử lý, chúng ta sẽ thấy địa chỉ của 5 biến cục bộ này có địa chỉ liên tiếp nhau.
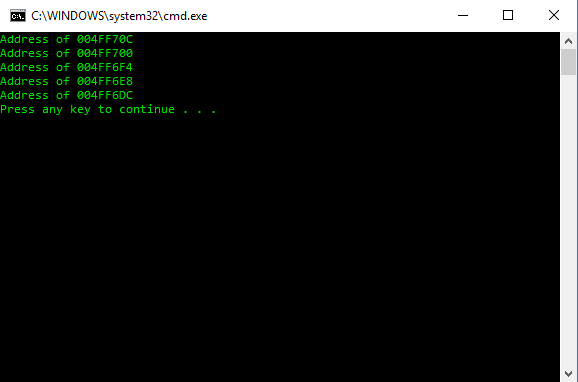
Địa chỉ sau cách địa chỉ trước đó đúng bằng kích thước của kiểu dữ liệu int.
Như vậy, lần lượt biến n1 n2 n3 n4 và n5 được cấp phát tại những địa chỉ tiếp theo (từ thấp đến cao) trên phân vùng Stack, và khi ra khỏi hàm main, lần lượt biến n5 n4 n3 n2 và n1 sẽ bị đưa ra khỏi Stack.
Stack overflow
Phân vùng Stack có kích thước khá hạn chế. Trên hệ điều hành Windows mà mình đang sử dụng, Call Stack chỉ có kích thước khoảng 1MB. Nếu chúng ta cố gắng cho chương trình cấp phát vùng nhớ trên Stack vượt quá kích thước của Stack, chúng ta gọi đó là hiện tượng tràn bộ nhớ phân vùng Stack (Stack overflow).
Một số ưu và nhược điểm có thể nhận thấy khi sử dụng phân vùng Stack
- Việc cấp phát bộ nhớ trên Call Stack khá nhanh.
- Nhìn vào mã nguồn chương trình, chúng ta có thể biết được thời điểm cấp phát và hủy vùng nhớ của biến trên Stack.
- Kích thước vùng nhớ cấp phát trên phân vùng Stack phải được khai báo rõ ràng trước khi biên dịch.
- Vùng nhớ trên phân vùng Stack có thể được truy cập trực tiếp thông qua định danh.
- Kích thước của phân vùng Stack khá hạn chế.
Tổng kết
Trong bài học này, chúng ta đã cùng tìm hiểu qua một số phân vùng bộ nhớ trên dãy địa chỉ bộ nhớ ảo. Còn một phân vùng nữa thuộc vùng dịa chỉ nhỏ nhất, đứng trước Code segment là phân vùng dành cho hệ điều hành. Vì hệ điều hành cũng là một chương trình (nhưng thuộc về hệ thống) nên nó cũng cần được load lên bộ nhớ ảo như những chương trình thông thường. Điều đặc biệt là phân vùng này ngăn chặn mọi hành vi truy cập từ phía người dùng, do đó mình không đề cập đến trong bài học này.
Hẹn gặp lại các bạn trong bài học tiếp theo trong khóa học lập trình C++ hướng thực hành.
Mọi ý kiến đóng góp hoặc thắc mắc có thể đặt câu hỏi trực tiếp tại diễn đàn
 mái thoải. (để tính trên
mái thoải. (để tính trên 
 83% thành viên diễn đàn không hỏi bài tập, còn bạn thì sao?
83% thành viên diễn đàn không hỏi bài tập, còn bạn thì sao?