
Cái này mới đầu mình nghĩ là dễ nhưng sau khi viết code thì hoá ra là chạy cứ lung tung beng cả lên, quá chậm hoặc ra kết quả không mong đợi. Nhờ mọi người vào hỗ trợ xem làm cách nào cho đơn giản, chính xác.
Yêu cầu của đề bài xem ra đơn gỉản: trích xuất những đoạn mà các dòng giống nhau ra mảng / hoặc file / in ra màn hình kiểm tra để sau đó xử lý.
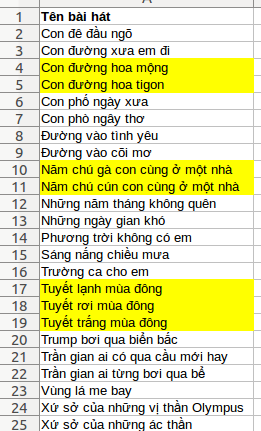
Gỉả sử đã có hàm similar_text trong PHP hoặc tương đương để quyết định thế nào là hai dòng text “gần giống nhau” và file text là lưu các chuỗi tiếng Việt có dấu, được đọc vào một mảng để xử lý.
Ý tưởng giải thuật của mình (cài đặt với PHP) là dùng vòng for hoặc while duyệt xuôi mảng, khi gặp trường hợp:
similar_text($line[$i], $line[$i+1], $ratio);
Nếu $ratio >= 90 thì chạy một vòng lặp khác duyệt ngược mảng và tìm chỗ cũng có ratio >=90, sau đó thì ta có được chỉ số (vị trí trong mảng) bắt đầu phân đoạn và kết đoạn các dòng giống nhau và trích ra thành một mảng con để sau đó in ra màn hình hoặc viết ra file.
Cuối cùng thì mình không làm sao chạy cho giống kết quả như trên hình hết. Nhờ các bạn vào phụ cho một tay.
Mình bổ sung: dữ liệu đã được sắp xếp để các dòng gần giống nhau đã nằm liền kề nhau rồi các bạn nhé.
Nếu các bạn viết OpCode hoặc cài đặt bằng PHP càng tốt nhé các bạn. À, những dòng tô vàng trên hình dữ liệu minh hoạ được xem là “gần giống nhau” theo như mình muốn nhé các bạn (và xin lỗi các bạn là thực sự những dòng trên không phải là tên bài hát,mà chỉ là dữ liệu minh hoạ ngẫu nhiên).
Xin cám ơn mọi người!
 83% thành viên diễn đàn không hỏi bài tập, còn bạn thì sao?
83% thành viên diễn đàn không hỏi bài tập, còn bạn thì sao?